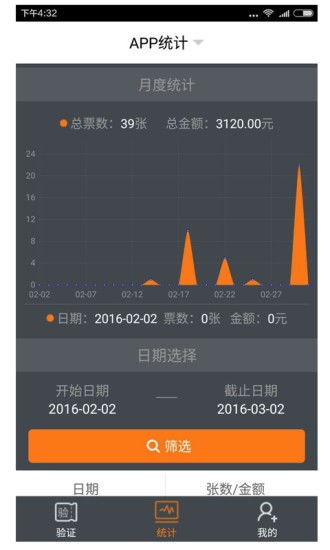
亞馬遜云科技(Amazon Web Services, AWS)宣布其無服務器大數據處理服務Amazon EMR Serverless正式在中國區域(由西云數據運營的寧夏區域和由光環新網運營的北京區域)上線。這一重要舉措標志著中國地區的企業用戶現在能夠以更簡單、更高效、更具成本效益的方式運行大規模數據處理與分析工作負載,無需預先配置、管理和擴展底層基礎設施。
Amazon EMR(Elastic MapReduce)是業界廣泛使用的大數據處理服務,支持包括Apache Spark、Apache Hive、Presto等在內的流行開源框架,用于大規模數據處理、交互式分析和機器學習任務。而此次上線的EMR Serverless是其無服務器版本,旨在進一步降低大數據分析的門檻與運維復雜性。
核心優勢:簡化運維與提升敏捷性
對于傳統的大數據集群,企業需要投入大量精力進行集群的規劃、配置、容量預估、擴縮容管理以及運行狀態監控,這不僅消耗了寶貴的技術資源,也影響了數據分析的敏捷性。Amazon EMR Serverless從根本上改變了這一模式:
- 無需管理基礎設施:用戶完全無需預置、配置或管理服務器、虛擬機或集群。只需提交Spark、Hive或Presto作業,服務會自動配置所需的計算和內存資源,并在作業完成后立即釋放資源。
- 自動彈性伸縮:服務會根據作業負載的變化,在幾秒鐘內自動、精細地擴縮計算資源,確保作業始終擁有合適的資源量,同時避免了資源閑置帶來的浪費。
- 按使用量付費:用戶僅需為作業實際使用的vCPU、內存和存儲資源付費,精確到秒,實現了真正的“用多少付多少”的成本模型,尤其適合間歇性、可變或不可預測的工作負載。
- 開源框架兼容性:完全兼容Apache Spark、Hive和Presto的開源版本,用戶現有的代碼、應用和庫無需修改即可遷移運行,保護了既有技術投資。
在中國區域的應用場景
隨著中國企業數字化轉型的深入,數據驅動的決策變得至關重要。Amazon EMR Serverless在中國區域的上線,將為眾多行業場景提供強大支持:
- 數據湖分析與ETL:企業可以輕松地對存儲在Amazon S3數據湖中的海量數據進行清洗、轉換和聚合,為商業智能報表和數據分析準備高質量的數據集。
- 交互式數據分析:數據分析師和業務人員可以通過熟悉的SQL工具(對接Hive或Presto)直接對數PB級別的數據執行即席查詢,快速獲取業務洞察。
- 流批一體處理:結合Apache Spark Structured Streaming,可以構建同時處理實時流數據和歷史批數據的統一管道,用于實時監控、實時報表和實時推薦等場景。
- 機器學習與數據科學:為大規模的特征工程、模型訓練和數據預處理提供彈性的計算平臺,加速AI/ML項目的迭代周期。
降低門檻,加速創新
亞馬遜云科技大中華區產品部總經理表示:“Amazon EMR Serverless在中國區域的推出,是我們持續將全球領先的云服務引入中國,賦能本地客戶創新的又一例證。它讓各種規模的企業,特別是那些缺乏專職大數據運維團隊的企業,能夠更專注于從數據中提取價值,而非管理基礎設施的復雜性,從而更快地將數據分析成果轉化為業務競爭力。”
對于已在使用Amazon EMR的中國用戶,可以無縫地將現有作業遷移至Serverless模式,享受更簡化的運維體驗和更優化的成本結構。對于尚未開始大數據之旅的企業,現在可以以極低的初始成本和運維負擔啟動項目,快速驗證想法并擴展業務。
Amazon EMR Serverless在中國區域的正式可用,為中國企業提供了一個現代化、高效且經濟的大數據處理解決方案,有望進一步推動各行業數據分析和智能應用的普及與深化。